
I Built a Vector Database for My Google Search Console Data & OpenClaw. Here's the Honest Truth About Whether You Need One.
Nowadays, I run OpenClaw as my primary SEO automation agent. It schedules tasks, generates content, monitors rankings, and handles the repetitive work that used to eat my mornings.

OpenClaw is an execution layer. It does what I tell it to. The problem is that I was the bottleneck. I had to manually dig through GSC charts via API, figure out which queries were declining, spot cannibalization issues, compare my content against competitors, and then come back and tell OpenClaw what to do about it. I often hit context limits.
I wanted to automate that discovery part too.
So I built a tool that pulls 16 months of Google Search Console data, processes it into structured documents with trend detection, embeds everything into a local vector database using Gemini’s embedding model, and lets any AI agent query it in plain English. I also wired up Parallel.ai so the system can crawl my pages and competitor pages for content gap analysis.
The whole thing is open source: github.com/metehan777/vectordb-gsc
This post is about what I learned building it, not a pitch for the tool. Some of what I learned made me question my own architecture choices.
The pipeline
Nothing fancy here.
The GSC API returns one row per query per page per date. For a site with real traffic over 16 months, that’s millions of rows. Step one is pulling all of that down.
Step two is where the actual value gets created. My data processor aggregates those raw rows into query-page pair documents. Instead of 50 separate daily rows for “seo audit checklist” on “/blog/seo-audit/”, I get one document that says: this query sent 4,200 clicks to this page over 16 months, average position 3.2, CTR 4.8%, and it’s on a declining trend because the last 4 weeks performed worse than the preceding 12.
That trend classification is probably the single most useful thing in the entire project.
Step three embeds those documents into ChromaDB using Gemini’s embedding model at 768 dimensions.
Step four is querying. I ask a question in English, the vector DB retrieves the most relevant documents, and an LLM analyzes them with an expert SEO system prompt. I can use Gemini Flash (free and fast), Grok 4.1 (2M token context window, so I can send it 400 documents instead of 50), or Claude Opus (tends to give more strategic recommendations).
For the audit and compete commands, Parallel.ai scrapes live web pages. My page. Competitor pages. The AI gets to see actual content side by side, not just metrics. That’s where the analysis goes from “your CTR is low” to “competitors have comparison tables, FAQ sections, and original data that you don’t.”
The part where I’m honest about the limitations
GSC data is structured. It’s numbers in columns. Clicks, impressions, CTR, position, date.
When I ask the vector database “find queries with high impressions but low CTR,” it doesn’t do arithmetic. It converts that sentence into a vector and finds documents whose text vectors are nearby in embedding space. That’s pattern matching on language, not math.
This means a SQL query like WHERE impressions > 1000 AND ctr < 0.03 ORDER BY impressions DESC would give me the mathematically correct answer. The vector DB gives me an approximation based on how similar the text looks. It might miss a query with 50,000 impressions because the text embedding didn’t land close enough. It might include a query with 200 impressions because the words in its description happened to match.
For anything involving specific thresholds, rankings by a metric, or aggregations like “average position across all pages,” SQL is objectively better.
Where the vector DB earns its place
But SQL has a blind spot that the vector DB fills.
Ask SQL “what content about AI is performing?” and you need a WHERE clause. WHERE query LIKE '%AI%' OR query LIKE '%artificial intelligence%' OR query LIKE '%machine learning%'. You have to enumerate every possible variation. You’ll miss “transformer architecture explained” and “neural network tutorial” because they don’t contain your keywords.
The vector DB handles this natively. The embedding model knows those concepts are related. It returns them without me having to list every synonym and subtopic.
The same applies to exploratory questions. “What’s happening with my technical SEO content?” is a perfectly valid query for the vector DB. For SQL, I’d need to already know which pages are about technical SEO before I can filter for them.
This semantic discovery is genuinely useful. It surfaces patterns I wouldn’t find by staring at spreadsheets.
The comparison I wish someone had made for me
Before I built this, I considered three approaches: a vector database (what I went with), a GSC MCP server (for real-time API access from AI agents), and a plain SQL database.
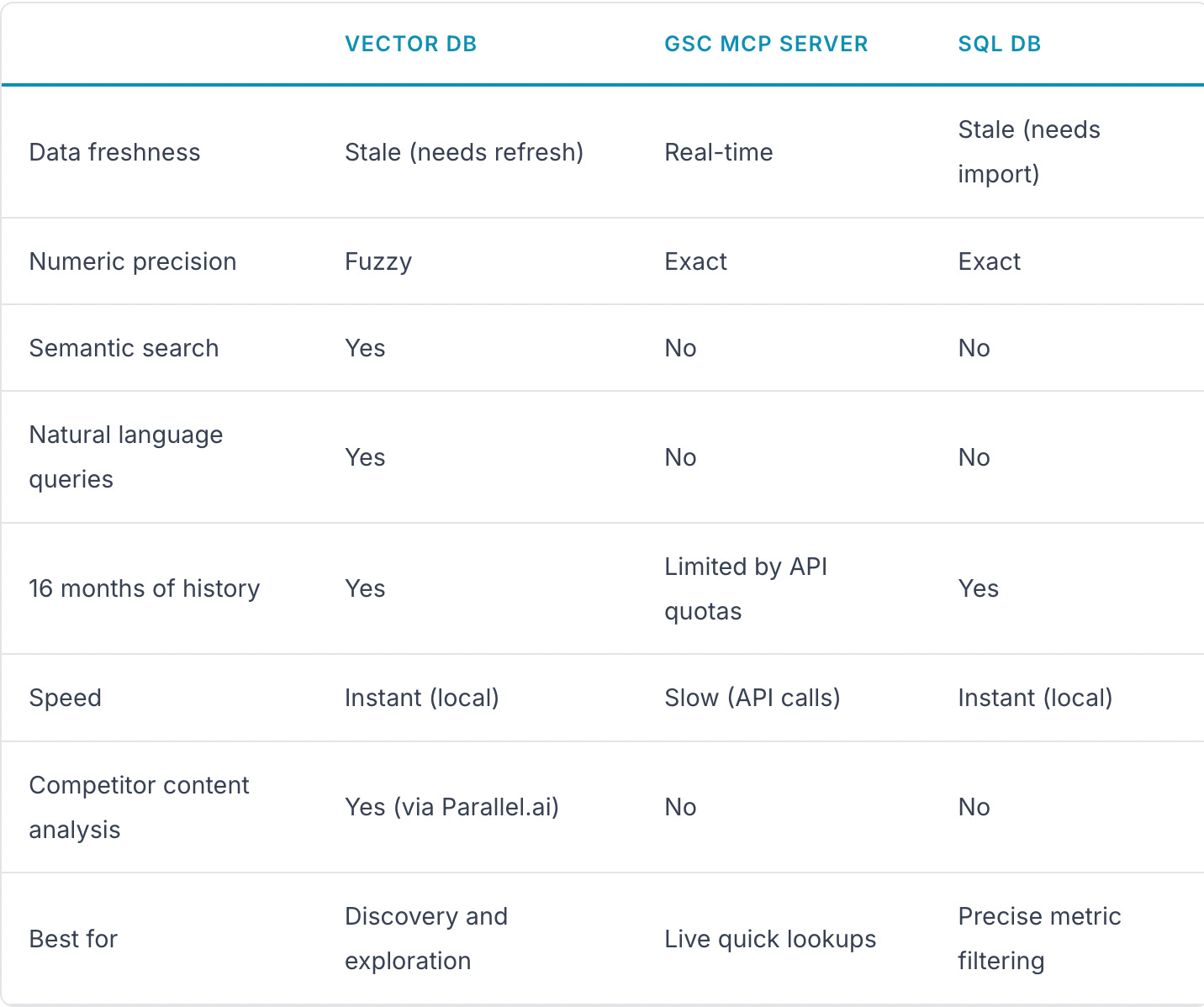
The ideal architecture would combine SQL and vector DB with an LLM routing layer that decides which backend to hit based on the question. I went pure vector DB because the exploratory analysis is where I personally get the most value. If I were building this for a client who needed exact metric reports, I’d add DuckDB alongside ChromaDB.
A GSC MCP server is fine for quick lookups, but you can’t do bulk analysis across 16 months through one. Every question is an API call. Rate limits hit fast. And it can’t crawl competitor pages.
How this works with OpenClaw
If you use OpenClaw for SEO, this tool fills a specific gap: persistent historical data with crawling ability.
My workflow looks like this:
A weekly cron job runs python main.py refresh to keep the vector database current. When I need strategic direction, I run python main.py ask "which topic clusters are declining?" --grok and get an analysis grounded in 16 months of data. When OpenClaw identifies a page that needs work, I run python main.py audit "https://metehan.ai/some-page/" --grok to get a full content gap report with competitor comparison. I feed that back to OpenClaw for execution.
OpenClaw does the work. The vector DB tells it where to focus.
The two tools complement each other because they solve different problems. OpenClaw is stateful (it remembers context across sessions) and action-oriented (it can write, publish, send emails). The vector DB is analytical. It knows what happened over 16 months and can surface patterns in that data. Together, they close the loop between “what should I work on?” and “get it done.”
You could also wrap these CLI commands into an OpenClaw skill so it queries your search data directly during workflows. The architecture is straightforward since everything runs locally.
What I’d change
If I were starting over, I’d store the structured metrics in DuckDB and only use the vector DB for semantic content (query text, page topics, content descriptions). The LLM would get exact numbers from SQL and semantic context from ChromaDB.
I’d also experiment with how I format the embedded documents. Right now, numerical values like “Clicks: 150” get baked into the text that gets embedded. Those numbers don’t carry real meaning in vector space. Separating them as metadata that gets attached after retrieval, rather than embedded with the text, would probably improve retrieval quality.
But the tool works well enough for what I use it for: finding patterns, discovering opportunities, and getting content recommendations that are backed by real data instead of generic SEO advice.
Open source, MIT licensed: https://metehan.ai/blog/i-turned-16-months-of-google-search-console-data-into-a-vector-database-heres-what-i-learned/
Awesome. I'll test this approach.
Cool stuff, Metehan!