
Reverse-Engineering Attention in GPT-OSS-20B (ChatGPT's Open Source Model)
A comprehensive weight-level analysis revealing how the model processes, routes, and generates content and how to architect your pages to align with its internal mechanisms.

This post is too technical. I mean 100x technical. But I know you love this type of content, right?
I recently tried to open a black box: ChatGPT’s open-source model GPT-OSS-20B.
The results are surprising a lot, and not.
Let’s start. It’s a very long post to read.
A comprehensive weight-level analysis revealing how the model processes, routes, and generates content and how to architect your pages to align with its internal mechanisms.
What I found changes how I think about content optimization for AI systems. Not because the findings are shocking, but because they’re so specific. The model doesn’t treat your content as a flat document. It runs it through a pipeline with distinct phases, and each phase has measurable biases that most people aren’t aware of.
I want to walk through the key findings here. Some of this gets technical, but I’ll try to keep the focus on what it means rather than how I measured it.
The architecture, briefly
GPT-OSS-20B is a Mixture-of-Experts transformer. That means it has 32 specialist sub-networks (called “experts”), but only activates 4 of them for each token it processes. It has 24 layers, 64 attention heads, and uses a 128-token sliding window for attention.
That last detail, the sliding window, turned out to be the most consequential finding for content structure. I’ll come back to it.
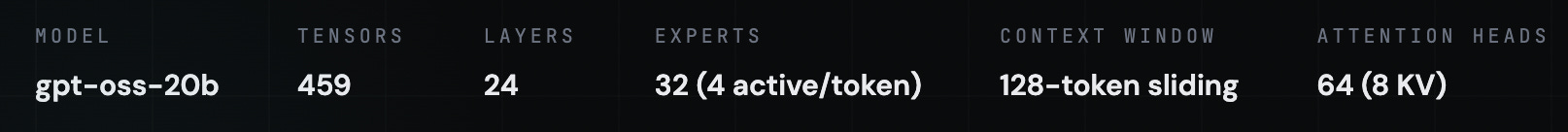
The model reads your first 50 tokens and makes a decision
The routing mechanism that decides which 4 experts process your content makes its decision early. I measured “specialization scores” across all 24 layers, and the peak is at layer 0, a score of 1.0278. By layer 5, the routing decision is essentially locked in. The gate bias standard deviation peaks at layer 2 (0.1804), meaning that’s where the model is most aggressively discriminating between content types.
In practical terms: the first ~50 tokens of your page determine which processing pathway your content takes. If your product page opens with three sentences of blog-style storytelling before mentioning what it actually is, the model may route it through the wrong expert pathway. The same goes for a technical guide that opens with promotional language.
I don’t think this means you need to be robotic about it. But the signal your content sends in its opening matters more than I previously assumed, and it matters at a mechanical level, not just a stylistic one.
The 128-token window and what happens at the edges
This is where I spent the most time, because the implications are concrete and somewhat unintuitive.
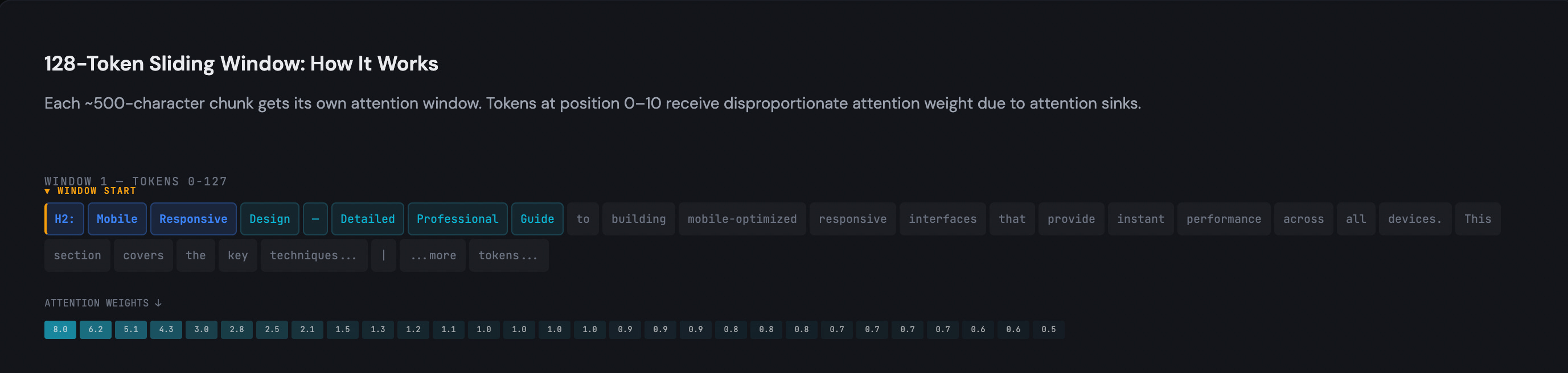
The model processes text in 128-token sliding windows, roughly 500 characters each. Within each window, tokens at the beginning (positions 0 through roughly 10) receive disproportionate attention. This is a known phenomenon in transformer research called “attention sinks,” but I hadn’t seen anyone measure it in a way that connects to content structure.
